Histograms
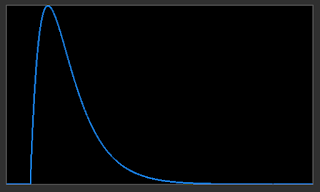
One of the most important tools for analysing astronomical images is the histogram. The histogram of the unprocessed astronomical linear image data shows clearly that the bulk of the pixels are cramped down at the bottom end of the magnitude scale as shown previously.
 |
Example Astronomical Image Luminance Histogram
|
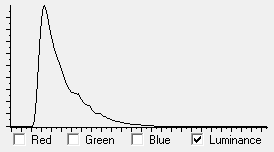
Also it was shown that the target for processing the image should spread the data values such that the bulk of the values lies around the 20 % - 25 % of the scale as shown below in the histogram of the 'everyday' image.
 |
| Everyday Image Luminance Histogram |
This is done by '
stretching' the data, where the data values down near the bottom are increased, while at the same time the bright values near the top are left as they are. The
stretching is done by some chosen non-linear function - but what and how ?
Recapping on the previous post concerning the form of the image data contained in stacked FITS files from the Seestar S50 - the data covers a range of an unsigned short integer (16-bits), that is, 0 - 65535. The histogram could have a bin size of 256 (as the histograms above have) - giving 256 separate bins. However, as the original linear data has been shown to be cramped down to the bottom few % of the magnitude, it is better to have a bin size of the value resolution, i.e., 1. Therefore, there are 65536 bins.
To create the histogram then entails creating an array of 65536 elements each holding an integer count. The array type needs to be an unsigned 32-bit integer (range 0 - 4,294,967,296) to ensure there is enough range for counts in an image of 1080 x 1920 pixels (if all the pixels were full white, then the count in one bin would be 1080 x 1920 = 2,073,600).
For a Seestar S50 stacked FITS file, therefore, you would only need 21 bits unsigned (or 22 bits signed). However, the next step up after 16-bits is 32-bits. Of course, 32-bit signed integers could be used as halving the positive range down to 2,147,483,648 provides ample headroom - but personally (as all values will be positive) I prefer to use unsigned integers as that gives a clue in the code of the nature (i.e., all positive) of the data contained therein.
Building the histogram is simply a matter of reading each pixel in the image (three passes as there are three colours) and incrementing the value in the array element indexed by the value as read.
PDF - (Probability Density Function)
Not to be confused with the PDF document format, the Probability Density Function is a way of normalising the information contained in the image histogram. In the histogram, the Y-axis is the count of the number of pixels which have the value of the bin index. The scale of that count depends on the size of the image - a larger image will tend to have a higher count in each of the bins compared to a smaller image. By dividing the count in each bin by the total number of pixels in the image we get a normalised PDF with a Y-axis range of 0.0 to 1.0. Now for each magnitude value (X-axis) we get a probability of that value occurring in the image.
The use of the term 'probability' might seem a bit pretentious given the PDF just described is just a normalised count - probability is usually reserved for some random value. However, the term is justified. Imagine standing on a pixel somewhere in the image. The PDF gives the probability that any random pixel any distance away will be a certain value. As any random pixel must have a value in the magnitude range, the total of the individual probabilities for all magnitude values must equal 1.0.
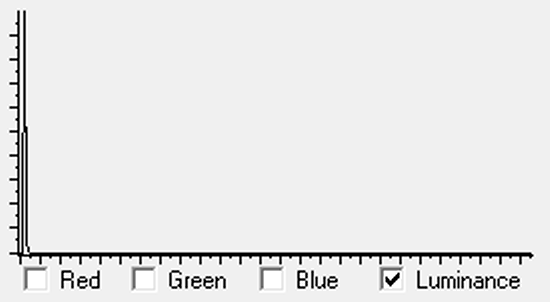
Note that the shape of the PDF is the same as the histogram - just the Y-axis scaling has been normalised. Note also that the maximum Y-axis value will lie somewhere below 1.0 - unless all pixels have the same magnitude value. The maximum Y-axis value therefore gives an indication of how clustered the values are. Comparing the two histograms above - the astronomical image has data that is 'clustered' at the bottom end, and so the maximum Y-axis value in the PDF would be close to 1.0. The everyday image - with magnitude values spread over a wider range - would have a maximum Y-axis value much lower.
The minimum value in the data can be found by traversing the PDF starting from the 0 magnitude value and finding the first magnitude value with a PDF > 0.0. The maximum value can be found by traversing the PDF starting from the top magnitude value (65535) and finding the lowest magnitude value where the PDF = 1.0.
CDF - (Cumulative Distribution Function)
The CDF is an integration of the PDF. The CDF for each magnitude value is the sum of the probabilities of that magnitude and all magnitudes below. This can be done empirically by doing a running sum of probabilities starting from the lowest magnitude. The Y values for the CDF always range between 0.0 and 1.0 - irrespective of the histogram and so give a means to compare characteristics of different images. The rather busy graph below shows the PDFs for a typical astronomical image and an everyday image (light red and light green bar charts respectively). The PDF for the astronomical image (light red bar chart) shows values are clustered down the bottom end. Its CDF (dark red) rises steeply at first, but then flattens off. The PDF for an everyday image (light green bar chart) shows values are more evenly spread across the range. Its CDF (dark green) rises almost linearly. Note that CDFs can only keep the same value or greater progressing from left to right across the graph. That is, it is monotonic increasing.
 |
| PDFs and CDFs of Astronomical and Everyday Images |
The upshot of the plotting of the CDFs is that we would want to somehow process the astronomical image data to have a CDF closer to the everyday image. How that is achieved is an interesting problem.
One aspect to consider here is that astronomical images typically have PDFs in which the values are significantly more clustered at the low end than even the example light red PDFA in the above graph. This means the CDFs will have an even steeper rise (reaches near 1.0 more quickly) than the dark red CDFA curve above. As key differences between such astronomical images lie in the low magnitude clusters, that area of the graphs needs to be zoomed into to reveal differences.